





I. L'article original▲
Qt Quarterly est une revue trimestrielle électronique proposée par Qt à destination des développeurs et utilisateurs de Qt. Vous pouvez trouver les versions originales.
Nokia, Qt, Qt Quarterly et leurs logos sont des marques déposées de Nokia Corporation en Finlande et/ou dans les autres pays. Les autres marques déposées sont détenues par leurs propriétaires respectifs.
Cet article est la traduction de l'article Querying Generic Data with XQuery de David Boddie paru dans la Qt Quarterly Issue 34.
Cet article est une traduction de l'un des tutoriels en anglais écrits par Nokia Corporation and/or its subsidiary(-ies), inclus dans la documentation de Qt. Les éventuels problèmes résultant d'une mauvaise traduction ne sont pas imputables à Nokia.
II. Introduction▲
Cette utilisation de XQuery pour valider et simplifier l'information pour des lecteurs XML peut faciliter la gestion de documents complexes, mais semble un peu inefficace pour lire un document, générer du XML et le lire à nouveau, même si le processus de lecture est beaucoup plus simple que sans XQuery.
Heureusement, nous avons trouvé que la classe QAbstractXmlNodeModel se débarrasse de cette étape supplémentaire inutile. Une instance de cette classe agit exactement comme un lecteur de flux XML ou un lecteur XML très classique, basé sur des événements, interprétant la sortie directement du moteur de requête pendant sa génération.
Maintenant que nous pouvons traiter du XML et l'interpréter d'une manière générale, nous allons reporter notre attention sur l'autre côté de QtXmlPatterns. Cet article va explorer les capacités du moteur de requête sur des sources de données non XML et la possibilité d'utiliser cette fonctionnalité sur des modèles de documents XML pour visualiser la sortie des requêtes.
III. S'adapter aux nouvelles données▲
Des données arbitraires peuvent être exposées au moteur de requête par l'API définie par la classe QAbstractXmlNodeModel, classe utilisée par le moteur pour accéder aux données dans une forme familière - comme des éléments, des attributs et des nœuds textuels - et pour naviguer dans ces données ; les instances de cette classe font leur possible pour adapter les données à ces contraintes.
La plupart des implémentations de l'API utilisent la classe QSimpleXmlNodeModel comme point de départ, en dérivant pour s'avantager partiellement de son comportement par défaut. La complexité des fonctions qui doivent être réimplémentées varie en fonction de la fonction et de la structure de données sous-jacentes en cours d'adaptation. Une implémentation de l'API va habituellement impliquer les fonctions listées ci-dessous.
Les deux premières fonctions s'occupent de l'information de haut niveau sur les données exposées par le modèle de nœud :
|
QUrl |
documentUri(const QXmlNodeModelIndex &nodeIndex) const |
|
QXmlNodeModelIndex |
root(const QXmlNodeModelIndex &nodeIndex) const |
Ces trois-ci gèrent les identités et les types d'items, déterminant la manière dont ils sont traités par le moteur de requête :
|
QXmlName |
name(const QXmlNodeModelIndex &nodeIndex) const |
|
QXmlNodeModelIndex::NodeKind |
kind(const QXmlNodeModelIndex &nodeIndex) const |
|
QVector<QXmlNodeModelIndex> |
attributes(const QXmlNodeModelIndex &element) const |
Les deux suivantes sont responsables du passage des représentations des valeurs des items (en opposition à leur nom) au moteur de requête :
|
QString |
stringValue(const QXmlNodeModelIndex &nodeIndex) const |
|
QVariant |
typedValue(const QXmlNodeModelIndex &nodeIndex) const |
Les deux dernières sont responsables de la fourniture d'informations sur l'ordre des nœuds et leur position relative dans le document, s'assurant que les opérations sur des chemins relatifs fonctionnent correctement sur le set de données :
|
QXmlNodeModelIndex::DocumentOrder |
compareOrder(const QXmlNodeModelIndex &nodeIndex1, const QXmlNodeModelIndex &nodeIndex2) const |
|
QXmlNodeModelIndex |
nextFromSimpleAxis(SimpleAxis axis, const QXmlNodeModelIndex &origin) const |
Nous allons les examiner en détail au fur et à mesure de l'implémentation de l'exemple. Cependant, un thème commun que nous pouvons voir dans cette API est l'utilisation d'objets QXmlNodeModelIndex. Tout comme le framework modèle-vue de Qt utilise QModelIndex pour faire référence à des objets d'une manière indépendante du modèle, cette API utilise QXmlNodeModelIndex pour faire référence à des items dans la structure de données.
IV. Un exemple simple▲
Pour montrer comment réimplémenter QAbstractXmlNodeModel et comment l'utiliser, nous présentons un exemple simple, dans lequel l'utilisateur effectue des recherches dans une structure de données personnalisée en utilisant des requêtes entrées dans un éditeur de texte. La structure de données décrit une collection de livres (Books), chacun représenté par une instance de la classe Book, contenant des champs titre et auteur.
|
Sélectionnez |
Sélectionnez |
Chaque champ est représenté par la classe Field. Au lieu de simplement stocker des données textuelles dans chaque champ, elles sont emballées dans des instances de la classe Text. Nous ajoutons ce niveau supplémentaire d'indirection pour créer une relation parent-enfant entre le texte et le champ le contenant et, par là, entre toutes les instances de ces classes. Finalement, chacune de ces classes contient un membre parent qui réfère à l'objet qui le contient.
Il est utile d'examiner la structure de données et de remarquer comment chaque item sera représenté avec des concepts XML, ainsi que de savoir si chaque morceau des données devra être exposé ou non au moteur de requête. Dans cet exemple, nous choisirons de représenter chaque objet Book en utilisant un élément book. Nous représenterons aussi les instances des autres classes en utilisant des éléments bien nommés. Cependant, les données contenues par chaque instance de Text seront représentées par un nœud textuel. Le parent de la collection est représenté par l'objet document.
Pour illustrer la relation parent-enfant, voici une implémentation Python de la classe Book :
class Book:
def __init__(self, title, authors):
self.title = Field(u"title", title, self)
self.authors = Field(u"authors", authors, self)
self.parent = None
def index(self, value):
if self.title == value:
return 0
elif self.authors == value:
return 1
else:
raise ValueError, repr(value) + " not a field in this book"La première chose à noter est que le parent est à l'origine indéfini. Cependant, quand un objet Book est ajouté à un conteneur Books, le parent est changé pour faire référence au conteneur. Les objets Books demandent au modèle du nœud d'en être le parent - ceci sera approfondi plus tard. Nous nous assurons que chaque objet Field a un objet Book comme parent en lui passant « self » à la création.
Observons ensuite la définition de la méthode index(). Elle est utilisée pour obtenir l'ordre des items enfants dans le livre. Ici, nous définissons le champ title en tant que premier enfant et le champ authors comme enfant suivant.
Nous examinons maintenant le modèle de nœud XML, BookModel, qui expose les instances de ces classes au moteur de requête.
class BookModel(QSimpleXmlNodeModel):
def __init__(self, books, namePool):
QSimpleXmlNodeModel.__init__(self, namePool)
self.books = books
self.books.parent = self
self.cache = {}Le constructeur de la classe accepte deux arguments : un objet Book, que nous mettons en relation avec le modèle en définissant son attribut parent, ainsi qu'une instance de QXmlNamePool. Cette liste de noms gère les noms pour une requête que nous créerons plus tard avec tous les objets liés qui doivent utiliser la même liste.
def documentUri(self, node_index):
item = self._getItem(node_index)
if item == self:
return QUrl("books://")
else:
return QUrl()La méthode documentUri() devrait retourner un identifiant unique pour le document, une URL non vide si cela est demandé. Ici, nous utilisons la convention que « self » (le modèle) fait référence au document. Nous utilisons la méthode _getItem() pour convertir l'index de modèle de nœuds, node_index vers un objet que nous pouvons reconnaître en tant qu'item de nos données.
Nous définissons deux méthodes pour convertir des objets en index et vice-versa. Elles utilisent un dictionnaire comme cache, mais certains bindings Python vous laissent utiliser la méthode createIndex() du modèle et la méthode correspondante internalPointer() pour effectuer les deux sens de la conversion.
def _createIndex(self, item):
self.cache[id(item)] = item
return self.createIndex(id(item))
def _getItem(self, node_index):
pointer = node_index.data()
if pointer:
return self.cache.get(pointer)
else:
return NoneAvec une manière de convertir les items en index et vice-versa, nous pouvons voir que la méthode root() retournera un index de modèle de nœud correspondant au modèle lui-même, le raccourci que nous utilisons pour le document. La racine est utilisée comme point d'entrée pour les requêtes.
def root(self, node_index = None):
return self._createIndex(self)
def name(self, node_index):
item = self._getItem(node_index)
if not item:
return QXmlName()
if isinstance(item, Books):
return QXmlName(self.namePool(), "books")
elif isinstance(item, Book):
return QXmlName(self.namePool(), "book")
elif isinstance(item, Field):
return QXmlName(self.namePool(), item.name)
else:
return QXmlName()La méthode name() fait exactement ce qu'on pourrait en attendre, vérifier les types de chaque item et retourner un QXmlName approprié qui peut être utilisé pour identifier l'item dans des requêtes. Tout ce que nous recevons et qui ne correspond pas à un élément reçoit un nom nul.
def kind(self, node_index):
item = self._getItem(node_index)
if isinstance(item, Text):
return QXmlNodeModelIndex.Text
elif item == self:
return QXmlNodeModelIndex.Document
else:
return QXmlNodeModelIndex.ElementLa méthode kind() est aussi assez simple, ne retournant que les types des items qu'on lui donne ; ceci est utilisé pour présenter les items en tant qu'éléments, attributs, nœuds textuels et racine du document. Comme de nombreuses autres parties de l'API, la fonction appelante garantit certaines choses sur l'index fourni. Dans ce cas, il doit garantir qu'il n'est pas nul et qu'il correspond à un item dans ce modèle, rendant l'implémentation de cette méthode beaucoup plus simple.
def attributes(self, element):
return []Pour chaque index de modèle de nœud correspondant à un item représenté comme un élément, la méthode attributes() retournera une collection d'index qui correspondent aux attributs de cet élément. Nous avons décidé de ne pas représenter la moindre partie de la structure de données en tant qu'attributs du XML. Par conséquent, nous pouvons retourner une liste vide - correspondant à un QVector vide.
def stringValue(self, node_index):
item = self._getItem(node_index)
if isinstance(item, Text):
return item.data
else:
return QSimpleXmlNodeModel.stringValue(self, node_index)
def typedValue(self, node_index):
item = self._getItem(node_index)
if isinstance(item, Text):
return QVariant(item.data)
else:
return QVariant()Bien que stringValue() ne soit pas absolument requise dans les dérivés de QSimpleXmlNodeModel, elle est appelée de préférence en lieu et place de typedValue() dans certains cas. Nous implémentons les deux méthodes pour retourner des valeurs pour des nœuds textuels.
La méthode compareOrder() est conceptuellement simple à écrire, mais peut nécessiter un peu de réflexion. Nous devons retourner une valeur indiquant si un item précède, suit ou est équivalent à un autre item dans la structure de données comme présentée au moteur de requête.
def nextFromSimpleAxis(self, axis, origin):
item = self._getItem(origin)
if not item:
return QXmlNodeModelIndex()
return_item = None
if isinstance(item, Text):
if axis == self.Parent:
return_item = item.parent
else:
if axis == self.Parent:
return_item = item.parent
elif axis == self.FirstChild:
if item == self:
return_item = self.books
elif isinstance(item, Books):
return_item = item.books[0]
elif isinstance(item, Book):
return_item = item.title
elif isinstance(item, Field):
return_item = item.text
elif axis == self.PreviousSibling:
if isinstance(item, Book):
index = item.parent.books.index(item)
if index > 0:
return_item = item.parent.books[index - 1]
elif isinstance(item, Field):
if item.name == u"authors":
return_item = item.parent.title
elif axis == self.NextSibling:
if isinstance(item, Book):
index = self.books.index(item)
if index < len(item.parent.books) - 1:
return_item = item.parent.books[index + 1]
elif isinstance(item, Field):
if item.name == u"title":
return_item = item.parent.authors
if return_item:
return self._createIndex(return_item)
else:
return QXmlNodeModelIndex()Une manière de gérer toutes les méthodes possibles de navigation dans le document est de vérifier le type de chaque item fourni comme origine, en gérant les nœuds textuels et les éléments séparément, puis d'appliquer l'axe à chacun.
Cette méthode est aussi garantie d'être appelée uniquement avec certaines combinaisons de valeurs d'arguments, éjectant les tentatives insensées de navigation vers le parent d'un document ou vers l'enfant d'un nœud textuel. Heureusement, elles sont documentées, rendant notre implémentation plus simple à écrire.
Avec le modèle BookModel écrit, nous pouvons maintenant donner quelques données à utiliser en vue de leur faire subir des requêtes. Le code requis pour définir les modèles est inclus dans une sous-classe de QMainWindow et peut être vu dans le code d'exemple disponible avec cet article. La partie intéressante pour nous est la méthode executeQuery(), que nous invoquons quand une action est déclenchée dans l'interface utilisateur.
En dehors de l'initialisation du gestionnaire de messages pour gérer le rapport d'erreurs, nous pouvons voir quelques classes familières et des objets utilisés. Un objet QXmlQuery est créé avec chaque instance de notre modèle. Notez que, comme mentionné plus haut, nous passons la liste de noms de requêtes au modèle à sa création.
def executeQuery(self):
query = QXmlQuery()
query.setMessageHandler(self.messageHandler)
self.bookModel = BookModel(self.books, query.namePool())
query.bindVariable(u"root", QXmlItem(self.bookModel.root()))
query_string = u"declare variable $root external;\n" + self.queryEdit.toPlainText()
query.setQuery(query_string)Avant de lancer une requête, nous devons nous assurer qu'elle opère sur notre modèle. Nous le vérifions en liant une variable de requête, root, à l'index correspondant au document et suffixant une déclaration à une chaîne de requête obtenue depuis un champ d'édition de texte. On attend de l'utilisateur qu'il utilise $root quand il veut se référer au document de notre modèle.
if query.isValid():
array = QByteArray()
buf = QBuffer(array)
buf.open(QIODevice.WriteOnly)
formatter = QXmlFormatter(query, buf)
if query.evaluateTo(formatter):
self.resultBrowser.setPlainText(QString.fromUtf8(array))
buf.close()La requête est évaluée avec les résultats passés dans un objet de formatage et écrits dans un tableau d'octets. Ceci est affiché dans un autre éditeur dans l'interface utilisateur.

L'exemple Books accompagnant cet article montre une petite collection limitée de livres, un navigateur de résultat et une fenêtre d'édition que vous pouvez utiliser pour entrer des requêtes - utilisez Ctrl+Return ou accédez au menu Query pour les exécuter.
L'exemple inclut quelques modèles de requêtes, qui peuvent être sélectionnées depuis le menu Insert.
V. Visualiser des requêtes▲
Maintenant que nous comprenons les techniques utilisées pour exposer les données au moteur de requête, nous pouvons faire des choses intéressantes. Par exemple, nous pouvons créer une structure de données qui comporte le contenu d'un document XML et appliquer des requêtes dessus au lieu de les appliquer sur le fichier XML lui-même. Ceci peut sembler un exercice redondant ; nous pouvons cependant emballer les données et leur structure dans l'API modèle-vue de Qt, ce qui nous permet de visualiser le document d'entrée à côté des résultats des requêtes.
L'image ci-dessous montre l'interface utilisateur pour l'exemple Visualize XQuery. Vous pouvez alors examiner quelles parties d'un document sont visitées par les requêtes et quelles parties arrivent finalement à la sortie. Comme l'exemple Books, ceci attend aussi que l'utilisateur fasse bon usage de $root comme référence à la racine du document d'entrée. Parce que cette technique est assez complexe, nous ne donnons que les trucs et techniques utilisés pour le créer et vous invitons à examiner le code source.
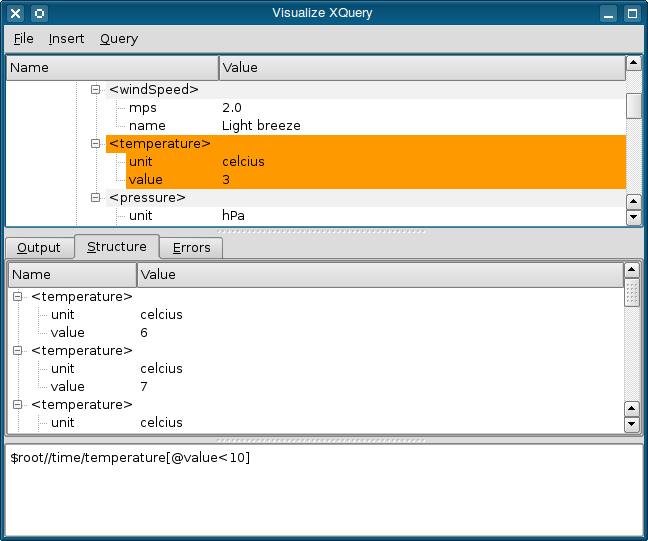
La partie supérieure de la fenêtre contient une représentation en arbre du document d'entrée - ceci utilise un modèle personnalisé, XmlItemModel, pour exposer le contenu du document XML à l'infrastructure modèle-vue de Qt, nous pouvons alors en afficher le contenu dans un widget QTreeView. La partie inférieure de la fenêtre contient un widget QPlainTextEdit où l'utilisateur compose des requêtes à appliquer sur le document d'entrée.
Le XmlItemModel représentant le document d'entrée contient un arbre d'objets XmlItem qui est construit avec une instance de XmlItemModelBuilder, un dérivé de QAbstractXmlReceiver, une classe que nous avons décrite dans l'article précédent. Le constructeur opère sur la sortie d'une requête qui liste tout le document pour produire un objet XmlItemModel à afficher dans un widget QTreeView.
Tout comme BookModel dans l'exemple Books opère sur des classes Books, Book, Field et Text, le XmlNodeModel de cet exemple opère sur un arbre d'objets XmlItem qui représentent le document d'entrée, autorisant les requêtes. En fait, les modèles XmlNodeModel et XmlItemModel opèrent sur le même arbre d'objets. Par conséquent, nous pouvons garder une trace des items visités par XmlNodeModel quand une requête est effectuée et ainsi ajuster leurs propriétés pour rendre visibles les changements à la vue, en montrant le contenu de XmlItemModel. Nous assombrissons la couleur d'arrière-plan de chaque item à chaque fois qu'il est visité pour distinguer ceux qui sont souvent ou non visités - ou pas du tout.
La vue créée dans l'onglet Structure montre le contenu d'un second XmlItemModel, créé grâce aux résultats de chaque requête effectuée sur le document d'entrée. À nouveau, une instance de XmlItemModelBuilder est responsable de la construction d'un modèle à des fins d'affichage. Les items créés par le constructeur sont différents de ceux du modèle représentant le document d'origine, nous ne pouvons donc pas directement faire correspondre les résultats de la requête avec les parties du document qui étaient sélectionnées. Cependant, nous pouvons exécuter la requête à nouveau et enregistrer le résultat dans un conteneur QXmlResultItems. Chaque XmlItem peut être tracé jusqu'à un QXmlNodeModelIndex qui peut correspondre à un item dans le modèle du document d'entrée. Le cas échéant, nous pouvons mettre en évidence l'item dans la vue, en changeant ses propriétés et mettant à jour la vue.
Puisque la requête peut créer des éléments complètement nouveaux, résultant en de nouveaux items et de nouveaux index de modèles de nœuds, il est parfois impossible de dire quelles parties du document d'entrée ont été transformées en résultats de requête. Bien que nous puissions visuellement inspecter le document d'entrée et dire quelles parties ont été sélectionnées par la requête, en utilisant la coloration pour nous aider, le cas de nouveaux éléments créés en utilisant des valeurs et attributs d'éléments avec des noms identiques dans le document d'origine se produit souvent. C'est ce qui arrive pour certaines requêtes types incluses dans l'exemple.
VI. En résumé et pour aller plus loin▲
Les deux exemples donnés dans cet article sont juste deux manières tirées par les cheveux d'utiliser les fonctionnalités du module QtXmlPatterns pour accéder à des données non XML, ne touchant que légèrement aux concepts entourant XML. Nous les considérons comme un point de départ pour une exploration plus approfondie et espérons qu'ils seront au moins utiles quand vous devrez visualiser et déboguer vos requêtes.
La documentation Qt contient quelques aperçus et exemples que vous pourriez trouver utiles.L'utilisation générale de XQuery et de la classe QXmlQuery est décrite en détail dans les documents suivants :
Ces exemples vous montrent comme exposer d'autres types de structures de données à XQuery :
La spécification du langage XQuery est aussi un document utile comme référence lors de la construction de requêtes complexes.
Le code source des exemples mentionnés dans cet article est aussi disponible.
VII. Divers▲
J'adresse ici de chaleureux remerciements à jacques_jean pour sa relecture !
Au nom de toute l'équipe Qt, j'aimerais adresser le plus grand remerciement à Nokia pour nous avoir autorisés à traduire cet article !